
大規模言語モデルLLMがいかに構築され、「追加学習」で進化するのか、そして「入力・指示」としての「プロンプト」が、どのようにLLMを動かし、望む結果を生み出すのか、その秘密を徹底解説。生成AIの複雑な「仕組み」を、開発・学習段階から生成・利用段階まで完全解剖します。
この記事を読めば、生成AIの全体像と、その裏側にある技術のが明確に理解できるでしょう。
生成AIとは何か その驚くべき能力と基本概念
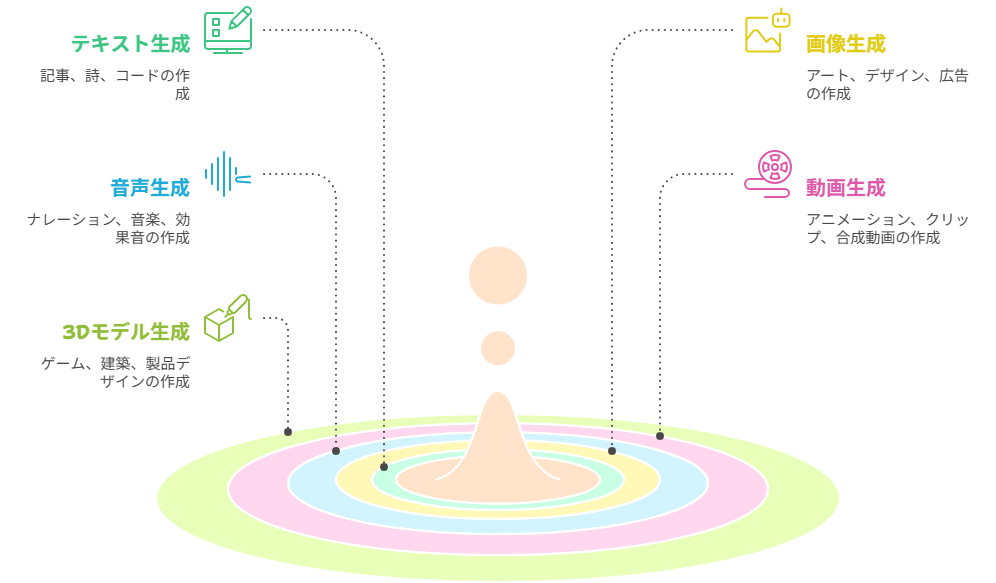
生成AIの定義と種類
生成AI(Generative AI)とは、既存のデータから学習し、その学習内容に基づいて、これまでに存在しなかった新しいテキスト、画像、音声、動画、プログラムコードなどのコンテンツを生成する人工知能を指します。単に情報を分析したり、パターンを認識したりするだけでなく、創造的なアウトプットを生み出す能力が最大の特徴です。
従来のAIが「認識」や「予測」を得意としていたのに対し、生成AIは「創造」という領域に踏み込みました。これにより、人間がゼロから生み出す必要があった作業の一部をAIが代替・支援できるようになり、その応用範囲は日々拡大しています。
生成AIは生成するコンテンツの種類によって多岐にわたります。代表的なものを以下に示します。
| 生成AIの種類 | 生成されるコンテンツ | 主な応用例 |
|---|---|---|
| テキスト生成AI | 文章、詩、小説、要約、翻訳、プログラムコード、チャット応答 | 記事作成、カスタマーサポート、プログラミング支援、議事録作成 |
| 画像生成AI | イラスト、写真、デザイン、アート作品 | 広告素材作成、コンセプトアート、ファッションデザイン、プレゼンテーション資料 |
| 音声生成AI | 自然な音声、歌声、効果音 | ナレーション、オーディオブック、バーチャルアシスタント、ゲーム開発 |
| 動画生成AI | 短いクリップ、アニメーション、合成動画 | プロモーションビデオ、SNSコンテンツ、教育コンテンツ |
| 3Dモデル生成AI | 立体モデル、テクスチャ | ゲーム開発、建築設計、製品デザイン |
特に、大規模言語モデル(LLM: Large Language Models)は、膨大なテキストデータを学習することで人間のような自然な文章を生成する能力を持ち、ChatGPTに代表されるように、その汎用性の高さから最も注目を集める生成AIの一つです。
大規模言語モデル(LLM)とは
生成AIのうち、大量の文章データを学習し、人間のように文章を理解・生成できるAIのことをいいます。自然言語(人間の言葉)に特化したモデルであることがその特徴です。
なぜ今生成AIが注目されるのか
生成AIがこれほどまでに社会の注目を集める背景には、いくつかの要因が複合的に絡み合っています。
技術的進化と普及の加速
過去数年間で、生成AIの基盤となる技術は飛躍的に進化しました。特に、Transformerアーキテクチャの登場と、計算能力の劇的な向上、そして大規模な高品質データセットの利用可能性が、現在の生成AIブームの原動力となっています。これにより、以前は想像もできなかったような複雑で多様なコンテンツを、短時間で高品質に生成することが可能になりました。
さらに、API(Application Programming Interface)やユーザーフレンドリーなインターフェースの提供により、専門的な知識がない一般ユーザーでも簡単に生成AIを利用できるようになりました。これにより、技術者だけでなく、クリエイター、ビジネスパーソン、学生など、あらゆる層に生成AIの活用が広まっています。
社会・経済へのインパクト
生成AIは、業務効率化、コスト削減、新たな価値創造という点で、社会や経済に計り知れないインパクトを与え始めています。
- 業務効率化と生産性向上: 文章作成、画像デザイン、プログラミングなどの定型業務や創造的作業をAIが支援することで、人間の作業時間を大幅に短縮し、生産性を向上させます。
- 新たなクリエイティブ表現の可能性: 誰でも高品質なコンテンツを生成できるようになり、個人の表現の幅を広げたり、これまでにないアートやエンターテイメントを生み出したりする土壌ができています。
- ビジネスモデルの変革: 生成AIを組み込んだ新しいサービスや製品が次々と登場し、既存の産業構造に変化をもたらしています。例えば、パーソナライズされたマーケティングコンテンツの自動生成や、AIを活用した顧客対応などが挙げられます。
- 研究開発の加速: 科学論文の要約、仮説生成、実験計画の支援など、研究開発のサイクルを加速させるツールとしても期待されています。
これらの要因が組み合わさることで、生成AIは単なる技術トレンドに留まらず、私たちの生活や働き方を根本から変える可能性を秘めた、「ゲームチェンジャー」として世界中で注目を集めているのです。
生成AIの「仕組み」全体像を把握する
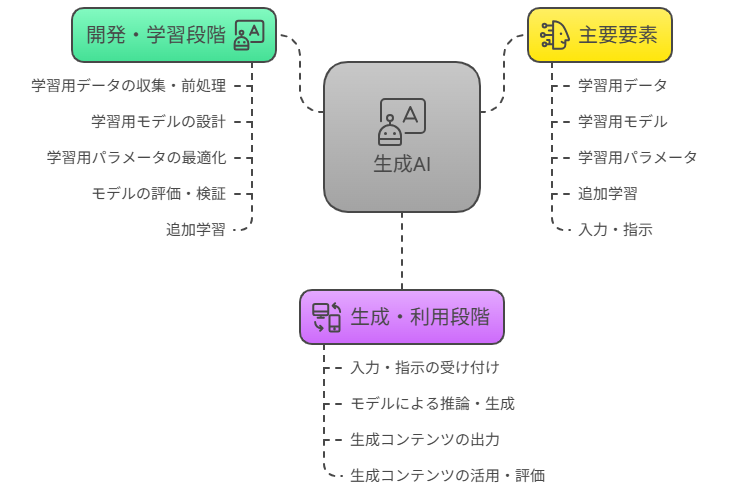
生成AIがどのように機能し、どのようなプロセスを経てコンテンツを生み出すのかを理解することは、その驚くべき能力の背景を知る上で不可欠です。ここでは、生成AIの開発から利用までの大きな流れと、それを構成する主要な要素について、全体像を把握していきます。
開発・学習段階と生成・利用段階のフロー
生成AIのライフサイクルは、大きく分けて「開発・学習段階」と「生成・利用段階」の二つのフェーズに分かれます。それぞれの段階で異なるプロセスが進行し、連携することで最終的なAIの機能が実現されます。
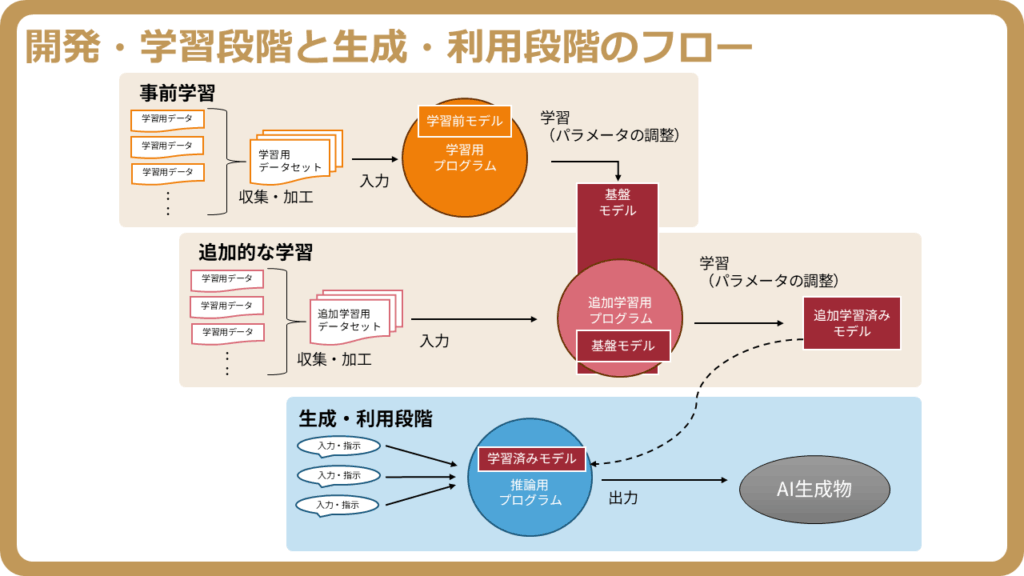
開発・学習段階では、AIが知識を獲得し、特定のタスクを実行できるようにするための基盤が築かれます。一方、生成・利用段階では、その基盤を用いてユーザーの要求に応じたコンテンツが実際に生成され、活用されます。
| フェーズ | 主なプロセス | 概要 |
|---|---|---|
| 開発・学習段階 | 学習用データの収集・前処理学習用モデルの設計学習用パラメータの最適化モデルの評価・検証追加学習(ファインチューニングなど) | 大量の学習用データセットを用いて、学習用モデル(特にLLMなど)に知識やパターンを習得させる段階です。この段階で、モデルの性能を決定づける学習用パラメータが調整され、必要に応じて追加学習が行われます。 |
| 生成・利用段階 | 入力・指示(プロンプト)の受け付けモデルによる推論・生成生成コンテンツの出力生成コンテンツの活用・評価 | 学習済みのモデルに対し、ユーザーが入力・指示(通称プロンプト)を与えることで、モデルが推論を行い、テキスト、画像、音声などのコンテンツを生成する段階です。生成されたコンテンツは、様々な目的で利用されます。 |
生成AIを構成する主要な要素
生成AIの複雑な仕組みは、いくつかの主要な要素が連携し合うことで成り立っています。これらの要素は、それぞれが特定の役割を担い、AIが学習し、コンテンツを生成するプロセス全体を支えています。
- 学習用データ(学習用データセット)
AIが学習するための基盤となる情報源です。テキスト、画像、音声など、様々な形式のデータが大量に集められ、学習用データセットとして整理されます。このデータの質と量が、AIの性能に直接的な影響を与えます。 - 学習用モデル(LLMなど)
学習用データからパターンや規則性を学び、新たなコンテンツを生成する「脳」にあたる部分です。特にテキスト生成においては、大規模言語モデル(LLM)がその中心的な役割を担います。モデルは、ニューラルネットワークなどの複雑なアーキテクチャで構成されています。 - 学習用パラメータ
モデルが学習する過程で調整される無数の数値です。これらのパラメータは、モデルがデータから得た知識や、異なる入力に対する応答の仕方を表現しています。学習が進むにつれて、これらのパラメータが最適化され、モデルの性能が向上します。 - 追加学習
一度学習が完了したモデルに対して、特定のタスクやドメインに特化させるために、さらに少量のデータで学習を行うプロセスです。これにより、汎用モデルを特定の用途にファインチューニングし、より専門的な能力を持たせることが可能になります。 - 入力・指示(プロンプト)
ユーザーが生成AIに何を生成してほしいかを伝えるためのテキストやデータです。特にテキストベースの生成AIにおいては、「プロンプト」と呼ばれる指示文が非常に重要になります。プロンプトの質が、生成されるコンテンツの質を大きく左右します。
これらの要素が相互に作用し、開発・学習段階でAIが知識を獲得し、生成・利用段階でその知識を基にプロンプトに従ってコンテンツを生み出すという一連の仕組みが成り立っています。
生成AIの開発・学習段階を徹底解説
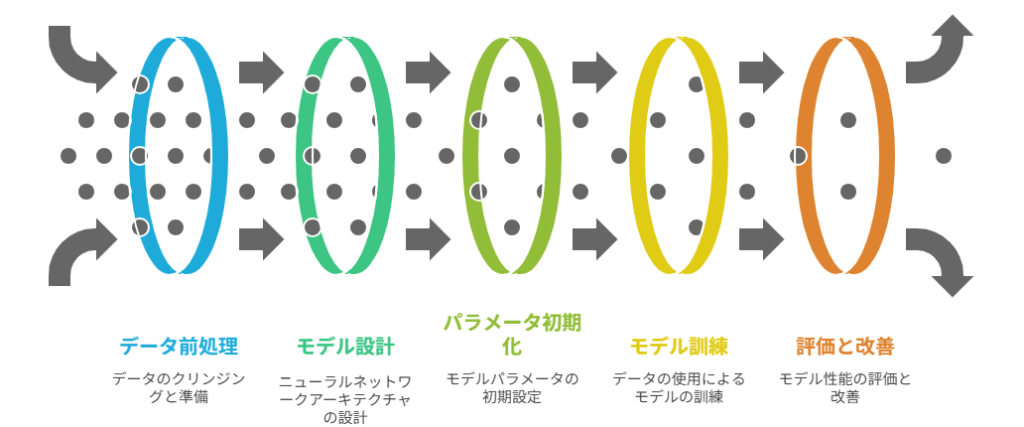
生成AIが私たちの生活やビジネスに革新をもたらす背景には、その「開発・学習段階」における精緻な仕組みが存在します。この段階は、生成AIが世界を理解し、新たなコンテンツを生み出す能力を獲得するための基盤を築く、最も重要なフェーズです。
生成AIの学習プロセス概要
生成AIの学習プロセスは、人間の学習に例えることができます。まず、大量の情報をインプットし(学習用データ)、その情報からパターンやルールを学び(学習用モデルとパラメータの調整)、最終的に新たな知識やスキルを習得する(生成能力の獲得)という流れです。
具体的には、以下のステップを経て生成AIは「賢く」なります。
- 学習用データの収集と準備: AIが学習するためのテキスト、画像、音声などの情報を集め、整理します。
- 学習用モデルの設計: どのような構造のニューラルネットワークを用いるかを決定します。特に大規模言語モデル(LLM)では、Transformerアーキテクチャが主流です。
- 学習用パラメータの初期化と調整: モデル内の「知識」を表現するパラメータを初期設定し、学習用データを用いて最適化していきます。
- 学習の実行: 準備されたデータを使ってモデルを訓練し、与えられたタスクをこなせるようにします。
- 評価と改善: 学習済みのモデルがどれだけ正確に、または適切に機能するかを評価し、必要に応じてデータやモデル、パラメータの調整を繰り返します。
この一連のプロセスが、生成AIの「仕組み」の根幹を成し、その性能を決定づけます。
学習用データと学習用データセットの重要性
生成AIの能力は、まさに「学習用データ」の質と量に大きく依存します。データはAIにとっての「経験」であり、この経験が豊富で適切であるほど、AIはより高度な判断や生成が可能になります。
高品質な学習用データとは
高品質な学習用データとは、単に量が多いだけでなく、以下の特性を持つものを指します。
- 多様性: 幅広いトピックやスタイル、形式を網羅していること。これにより、AIは様々な状況に対応できる汎用性を獲得します。
- 正確性: 事実に基づき、誤りや矛盾がないこと。誤った情報で学習すると、AIも誤った出力をする可能性があります。
- 偏りのなさ: 特定の視点や属性に偏らず、公平なデータであること。偏りがあると、AIの出力にもバイアスが生じる恐れがあります。
- 最新性: 必要に応じて、最新の情報が含まれていること。特に急速に変化する分野では重要です。
- 倫理的配慮: 著作権やプライバシーを侵害しない、倫理的に適切なデータであること。
例えば、テキスト生成AIの場合、書籍、記事、ウェブサイト、会話記録など、多様なジャンルの高品質なテキストデータが求められます。画像生成AIであれば、高解像度で様々な被写体や構図、スタイルの画像データが必要です。
学習用データセットの構築と前処理
収集された生データは、そのままAIの学習に使えるわけではありません。効果的な学習を可能にするためには、「学習用データセット」として適切に構築し、前処理を行う必要があります。
主な前処理のステップは以下の通りです。
| ステップ | 内容 | 目的 |
|---|---|---|
| データクレンジング | ノイズ(誤字脱字、不要な記号、重複データなど)の除去、欠損値の補完。 | データの品質向上、学習効率の改善。 |
| 正規化・標準化 | データのスケールを揃える、形式を統一する(例:テキストの小文字化、画像のサイズ調整)。 | モデルがデータを均等に扱えるようにする。 |
| トークン化(テキストの場合) | 文章を単語やサブワードなどの「トークン」に分割する。 | モデルがテキストを数値として処理できるようにする。 |
| アノテーション・ラベリング | データにタグやラベルを付与する(例:画像内のオブジェクトに境界ボックスをつける、テキストに感情ラベルをつける)。 | 教師あり学習において、モデルが何を学ぶべきかを明確にする。 |
| データ分割 | 学習用(訓練)、検証用、テスト用にデータを分割する。 | モデルの汎化性能を適切に評価するため。 |
これらの前処理を経て構築された「学習用データセット」が、生成AIの「知識の源」となります。
学習用モデルの設計と役割
「学習用モデル」は、学習用データからパターンを抽出し、新たな情報を生成するための「脳」に相当します。その中心となるのがニューラルネットワークと深層学習の技術です。
ニューラルネットワークと深層学習の基礎
ニューラルネットワークは、人間の脳の神経細胞(ニューロン)の仕組みを模倣した数理モデルです。複数の層にわたるノード(人工ニューロン)が結合し、情報が伝達されることで学習を行います。
- 入力層: データの情報を受け取る最初の層。
- 隠れ層: 入力された情報から特徴を抽出し、複雑なパターンを学習する層。深層学習では、この隠れ層が多数(深層に)存在します。
- 出力層: 学習の結果として、予測や生成を行う最終層。
各ノードは、前の層からの入力に「重み」を掛け合わせ、合計し、「バイアス」を加えて、活性化関数を通して次のノードに情報を伝達します。この「重み」と「バイアス」が、モデルが学習する「知識」そのものとなります。
深層学習は、このニューラルネットワークの隠れ層を多層にすることで、より複雑で抽象的な特徴を自動的に学習できるようになった技術です。これにより、画像認識、音声認識、自然言語処理といった分野で飛躍的な進歩がもたらされました。
大規模言語モデルLLMのアーキテクチャ
生成AIの中でも特に注目される「大規模言語モデル(LLM)」は、深層学習の一種であり、テキスト生成において驚異的な能力を発揮します。その多くは「トランスフォーマー」という特定のアーキテクチャに基づいています。
トランスフォーマーモデルの核心は、「アテンションメカニズム(注意機構)」にあります。これは、入力された文章の各単語が、他のどの単語と関連性が高いかを自動的に判断し、その関連性に基づいて情報を処理する仕組みです。これにより、文章全体の関係性を深く理解し、文脈に沿った自然なテキストを生成することが可能になります。
LLMは、膨大なテキストデータ(例えばGPT-4の場合、数兆トークン規模)で事前学習を行うことで、言語の文法、意味、世界の常識、さらには推論能力までを暗黙的に学習します。この学習された知識が、後にユーザーの「プロンプト」に応答する際の基盤となります。
学習用パラメータの調整と最適化
「学習用パラメータ」は、生成AIモデルが学習した知識そのものです。これらのパラメータを適切に調整し、最適化することが、モデルの性能を最大限に引き出す鍵となります。
モデルの学習におけるパラメータの役割
ニューラルネットワークにおけるパラメータとは、具体的には各ニューロン間の結合の強さを表す「重み(Weights)」と、各ニューロンの発火しやすさを調整する「バイアス(Biases)」のことです。モデルが学習用データからパターンを学ぶ過程で、これらの重みとバイアスの値が徐々に更新されていきます。
例えるなら、重みとバイアスは、AIが世界をどのように「認識」し、入力に対してどのような「反応」をするかを決定する「ダイヤル」のようなものです。学習プロセスは、これらのダイヤルを最適な位置に調整する作業と言えます。
学習が完了すると、これらのパラメータの集合が、モデルが獲得した知識(例えば、言語のルール、画像のパターン、音の特徴など)を表現することになります。
パラメータの最適化手法
パラメータの最適化は、「損失関数(Loss Function)」と「最適化アルゴリズム(Optimizer)」を用いて行われます。
- 損失関数: モデルの出力と正解データとの「誤差」や「ずれ」を数値化する関数です。この損失関数の値が小さければ小さいほど、モデルの性能が良いと判断されます。
- 最適化アルゴリズム: 損失関数の値を最小化するように、パラメータ(重みとバイアス)を効率的に更新していく手法です。最も基本的なものは「勾配降下法(Gradient Descent)」であり、損失関数の勾配(傾き)を利用して、損失が減少する方向にパラメータを少しずつ調整します。
勾配降下法には、確率的勾配降下法(SGD)、Adam、RMSpropなど、様々な改良版が存在し、それぞれ異なる特性を持ちます。これらの最適化アルゴリズムは、「学習率(Learning Rate)」というハイパーパラメータ(学習前に人間が設定する値)によって、パラメータの更新幅が調整されます。適切な学習率の設定は、効率的な学習と性能向上に不可欠です。
このパラメータの調整と最適化の繰り返しによって、生成AIモデルは与えられたタスクに対してより正確で適切な出力を生み出せるようになります。
追加学習のメカニズムと活用
生成AIモデルは一度学習を終えたら終わりではありません。特定のタスクや最新の情報を反映させるために、「追加学習」が行われます。これは、既存のモデルの知識を基盤として、さらに特定の目的のために学習を重ねるプロセスです。
事前学習とファインチューニング
生成AI、特にLLMの学習プロセスは、大きく「事前学習(Pre-training)」と「ファインチューニング(Fine-tuning)」の2段階に分けられます。
| 学習段階 | 目的 | 使用データ | 特徴 |
| 事前学習 | 汎用的な知識の獲得 | 大量の多様なデータ(インターネット上のテキスト、画像など) | モデルの基盤となる膨大な知識(言語の文法、世界の常識、画像の特徴など)を学習。計算コストが非常に高い。 |
| ファインチューニング | 特定タスクへの適応・専門化 | 特定のドメインやタスクに特化した少量のデータ | 事前学習で得た知識を活かし、特定の目的(例:カスタマーサポート、医療診断、特定の文体での文章生成)に合わせてモデルを微調整。計算コストが比較的低い。 |
ファインチューニングは、事前学習済みのモデルのパラメータを、特定のタスクデータでさらに学習させることで、そのタスクに対する性能を大きく向上させる方法です。近年は、モデル全体を再学習する従来型に加え、LoRA(Low-Rank Adaptation)やPEFT(Parameter-Efficient Fine-Tuning)といった、モデルの一部パラメータのみを効率的に更新する手法が普及しています。これにより、計算資源や学習データを大幅に削減しつつ、特定のニーズに適した生成AIを短期間で構築することが可能になっています。
転移学習による応用範囲の拡大
ファインチューニングは、「転移学習(Transfer Learning)」という概念の具体的な応用例です。転移学習とは、あるタスクで学習済みのモデルが獲得した知識や特徴表現を、別の関連するタスクに応用する技術を指します。
生成AIの文脈では、大規模なデータで事前学習された汎用的なモデル(例:GPTシリーズ、BERTなど)が、その後の様々な特定タスク(例:感情分析、質問応答、要約、特定の分野の文章生成)において、ベースモデルとして活用されます。これは、汎用モデルがすでに言語や世界の基本的な構造を理解しているため、新しいタスクの学習をゼロから始める必要がなく、少量のデータでも高い性能を発揮できるためです。
転移学習により、生成AIの応用範囲は飛躍的に拡大し、様々な業界や用途でカスタマイズされたAIソリューションの開発が加速しています。これは、限られたリソースでも高性能な生成AIを構築できる、非常に強力な「仕組み」と言えます。
生成AIの生成・利用段階を徹底解説

生成AIの真価は、その学習が完了した後に発揮されます。この章では、学習済みの生成AIモデルがどのようにユーザーからの入力に応答し、新たなコンテンツを生成するのか、その「生成・利用段階」の仕組みを詳細に解説します。
生成AIの推論プロセス
生成AIの「推論プロセス」とは、学習済みのモデルが新しいデータ(入力・指示)を受け取り、それに基づいて予測やコンテンツ生成を行う一連の流れを指します。学習段階で獲得した知識とパターン認識能力を基に、入力された情報から最も妥当な、あるいは創造的な出力を導き出します。
具体的には、ユーザーからの入力はモデルが理解できる形式(数値ベクトルなど)に変換され、モデル内部の複雑なニューラルネットワークを順次通過します。この際、モデルは学習時に調整された「学習用パラメータ」を用いて、入力された情報と過去の学習データとの関連性を分析し、次の出力要素(例:単語、ピクセル、コードの一部)を確率的に予測していきます。この予測と生成を繰り返すことで、最終的なコンテンツが構築されます。このプロセスは、特に大規模言語モデル(LLM)においては、与えられたプロンプトに基づいて、次に続く可能性が最も高い単語(トークン)を次々と予測していく形で進行します。
入力・指示の重要性とプロンプトの役割
生成AIは、ユーザーからの「入力」や「指示」がなければ何も生成できません。この入力・指示の中でも、特にユーザーの意図をAIに正確に伝え、望む出力を引き出すための具体的な指示文を「プロンプト」と呼びます。プロンプトの質が、生成されるコンテンツの品質、関連性、有用性を大きく左右するため、その設計は極めて重要です。
ユーザーの意図を伝える入力方法
生成AIにユーザーの意図を伝える方法は、主に自然言語を用いたテキスト入力が中心となります。効果的な入力を行うためには、以下の点を意識することが重要です。
- 明確性: 何を生成してほしいのか、具体的な目的を明確に記述します。曖昧な表現は避け、誤解の余地がないようにします。
- 具体性: 生成してほしいコンテンツの形式、スタイル、トーン、長さなど、具体的な制約や条件を詳細に指定します。
- 文脈の提供: AIが生成すべきコンテンツの背景や関連情報を提供することで、より適切で質の高い出力を促します。
- 例示(Few-shot prompting): 望む出力の形式や内容を、いくつかの具体例(入力と出力のペア)を示すことで、AIに学習させる手法です。これにより、より複雑な指示や特定のスタイルへの対応が可能になります。
プロンプトエンジニアリングの基本
「プロンプトエンジニアリング」とは、生成AIから望ましい出力を得るために、効果的なプロンプトを設計・最適化する技術です。これは、単に質問を投げかけるだけでなく、AIの特性を理解し、その能力を最大限に引き出すための戦略的なアプローチを伴います。以下に、プロンプトエンジニアリングの基本的なテクニックを示します。
| テクニック | 概要 | 具体例 |
|---|---|---|
| 明確な指示 | AIに何をさせたいか、具体的なタスクを簡潔かつ明確に伝える。 | 「この文章を要約してください。」「500字以内でブログ記事を作成してください。」 |
| 役割設定(ペルソナ) | AIに特定の役割や専門家としての立場を与えることで、その視点からの出力を促す。 | 「あなたはプロのマーケターです。この新製品のキャッチコピーを考えてください。」 |
| 制約条件の指定 | 出力の形式、長さ、含めるべき要素や避けるべき要素などを指定する。 | 「箇条書きで3つ提案してください。」「ポジティブなトーンで、ネガティブな言葉は使わないでください。」 |
| 例示(Few-shot) | 入力と出力のペアをいくつか提示し、AIにパターンを学習させる。 | 「入力:りんご → 出力:果物。入力:トマト → 出力:野菜。入力:きゅうり → 出力:?」 |
| 思考の連鎖(Chain-of-Thought) | AIに中間的な思考ステップを生成させることで、複雑な問題解決能力を向上させる。 | 「この問題を解くには、まずどう考えますか?ステップバイステップで説明してください。」 |
| 出力形式の指定 | JSON、HTML、箇条書きなど、特定の出力形式を指示する。 | 「以下の情報をJSON形式で出力してください。」 |
これらのテクニックを組み合わせることで、ユーザーは生成AIの能力を最大限に引き出し、より精度の高い、あるいは創造的な結果を得ることが可能になります。プロンプトエンジニアリングは、生成AIの活用において不可欠なスキルとなりつつあります。
プロンプトがLLMを動かす秘密
大規模言語モデル(LLM)がプロンプトに応答し、自然な文章を生成できるのは、その内部に学習された膨大な言語知識と、プロンプトを解釈し、次のトークンを予測する複雑なメカニズムがあるためです。
LLMがプロンプトを解釈する仕組み
LLMがプロンプトを解釈するプロセスは、主に以下のステップで進行します。
- トークン化: まず、入力されたプロンプトは、LLMが処理できる最小単位である「トークン」に分割されます。トークンは単語、句読点、あるいは文字の一部など、モデルによって定義された単位です。
- 埋め込み(Embedding): 各トークンは、その意味や文脈を表す数値ベクトル(埋め込みベクトル)に変換されます。これにより、単語間の意味的な関係性や類似性が数値的に表現され、モデルが言語を「理解」するための基盤となります。
- アテンションメカニズム: LLMの核となるTransformerアーキテクチャでは、「アテンションメカニズム」が重要な役割を果たします。これは、プロンプト内の各トークンが、他のどのトークンと関連性が高いかを動的に判断し、その関連性に基づいて情報を重み付けする仕組みです。これにより、モデルは文脈全体を把握し、特定の単語が文章のどの部分に影響を与えるかを理解できます。例えば、「彼」という代名詞が文章中の誰を指すのかを正確に特定するのに役立ちます。
- 次トークン予測: これらの情報(トークン、埋め込み、アテンション)を基に、LLMは次に続く可能性が最も高いトークンを確率的に予測します。この予測されたトークンが新たに追加され、再び次のトークンが予測されるというプロセスを繰り返すことで、一連の文章が生成されていきます。この繰り返しによって、プロンプトの意図に沿った、論理的で自然な文章が構築されます。
この一連のプロセスは、LLMが学習段階で獲得した膨大なテキストデータからのパターン認識と、統計的な確率推論に基づいて行われます。プロンプトは、この複雑な内部メカニズムを起動させる「トリガー」として機能し、学習済みの知識を引き出し、特定の方向へと出力を導く役割を担っています。
プロンプトの質が生成結果に与える影響
プロンプトの質は、生成AIの出力に直接的かつ劇的な影響を与えます。これは「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」という原則が生成AIにも当てはまるためです。
- 曖昧なプロンプト: ユーザーの意図が不明確なプロンプトは、モデルが何を生成すべきか判断できず、無関係な内容、一般的な回答、あるいはハルシネーション(Hallucination:事実に基づかない誤った情報)を引き起こす可能性が高まります。
- 具体的なプロンプト: 明確で具体的なプロンプトは、モデルがユーザーの要求を正確に理解し、高品質で関連性の高い、意図通りのコンテンツを生成する確率を格段に高めます。出力の形式、トーン、スタイル、長さなども細かく制御できるようになります。
- 安全性と倫理: 不適切または悪意のあるプロンプトは、差別的、暴力的、あるいは不正確なコンテンツを生成させるリスクがあります。逆に、倫理的なガイドラインや安全に関する制約をプロンプトに含めることで、より安全で責任ある出力を促すことができます。
したがって、生成AIを効果的に利用するためには、プロンプトの設計に時間と労力をかけ、意図を正確に反映した質の高いプロンプトを作成するスキルが不可欠です。
生成されたコンテンツの活用と評価
生成AIによって生み出されたコンテンツは、多岐にわたる分野で活用されていますが、その品質を適切に「評価」し、必要に応じて改善することは、実用化において非常に重要です。
生成されるコンテンツは、テキスト(記事、詩、コード、要約、翻訳)、画像(イラスト、写真、デザイン)、音声(ナレーション、音楽)、動画など多岐にわたります。これらは、コンテンツ作成の効率化、アイデア出し、パーソナライズされた体験の提供、特定のタスクの自動化など、様々な目的で活用されます。
しかし、生成されたコンテンツは常に完璧であるとは限りません。そのため、以下の観点から評価を行う必要があります。
- 正確性: 事実に基づいているか、誤情報を含んでいないか。特に情報提供を目的とするコンテンツでは最も重要です。
- 関連性: プロンプトの意図や文脈に合致しているか、ユーザーの期待に応えているか。
- 品質: 自然な表現か、文法的な誤りはないか、論理的な一貫性があるか、美的センスはどうか。
- 安全性と倫理性: 差別的、暴力的、不適切、あるいは著作権を侵害するような内容が含まれていないか。
- 有用性: ユーザーの目的達成に役立つか、具体的な問題解決に貢献するか。
これらの評価は、多くの場合、人間の目による確認(Human-in-the-Loop)が不可欠です。生成されたコンテンツをそのまま利用するのではなく、必ず人間がレビューし、必要に応じて編集・修正を加えることで、最終的な品質を保証し、リスクを低減することができます。また、この評価プロセスから得られたフィードバックは、プロンプトの改善や、さらにはモデルの追加学習(ファインチューニング)に活用され、将来の生成品質向上へと繋がります。
生成AIの未来と進化の展望

生成AIは、すでに私たちの生活やビジネスに大きな影響を与え始めていますが、その進化はまだ始まったばかりです。開発・学習段階における技術革新と、生成・利用段階での応用範囲の拡大が相まって、生成AIは今後も指数関数的な進化を遂げ、社会のあり方を根本から変革する可能性を秘めています。 この章では、生成AIがもたらす未来の可能性と、その実現に向けて乗り越えるべき課題について深掘りします。
生成AIの応用事例と可能性
生成AIの応用範囲は、テキスト生成にとどまらず、画像、音声、動画、さらには3Dモデルやコード生成など、多岐にわたります。これまでの「学習用データセット」の多様化と「LLM」をはじめとする「学習用モデル」の高性能化により、ユーザーの「入力・指示」、すなわち「プロンプト」一つで、かつては専門家でなければ生み出せなかったような高品質なコンテンツやソリューションが瞬時に生成可能になっています。
| 分野 | 具体的な活用例 | 関連する生成AIの仕組み |
|---|---|---|
| コンテンツ生成 | ブログ記事、広告コピー、小説、詩の自動生成、イラスト、写真、動画の作成、音楽の作曲 | 多様な「学習用データセット」による表現力、「LLM」による文脈理解、「プロンプト」による細かな指示 |
| 業務効率化 | 議事録の要約、メール作成支援、データ分析レポートの自動生成、プログラミングコードの自動補完・生成 | 「学習用モデル」の推論能力、「追加学習」による特定業務への適応、「プロンプト」によるタスク指示 |
| 医療・科学 | 新薬候補物質の設計、分子構造の予測、医療画像の診断支援、研究論文の要約 | 専門性の高い「学習用データ」と「学習用モデル」の連携、「学習用パラメータ」の精密な調整 |
| 教育 | 個別最適化された教材の作成、学習者の理解度に応じた問題生成、語学学習の対話パートナー | 「学習用データセット」の網羅性、「LLM」による自然な対話、「プロンプト」による学習進捗の調整 |
| エンターテイメント | ゲーム内のキャラクター対話、仮想空間における環境生成、インタラクティブなストーリーテリング | 「学習用モデル」の創造性、「プロンプト」によるユーザー体験のパーソナライズ |
これらの応用は、単なる自動化に留まらず、人間の創造性を刺激し、新たな価値を生み出す「協調」のツールとしての役割を強めています。
今後の課題と技術的進化
生成AIの急速な進化は、期待とともにいくつかの重要な課題も浮上させています。これらの課題への対応と、さらなる技術的進化が、生成AIの健全な発展と社会への貢献を左右するでしょう。
生成AIが直面する課題
現在、生成AIは以下のような課題に直面しています。
- ハルシネーション(幻覚): 事実に基づかない情報を生成してしまう問題は、特に「LLM」において顕著です。これは「学習用データセット」の偏りや、「学習用モデル」の推論メカニズム、生成過程の確率性などに起因することがあります。
- バイアス(偏見): 「学習用データ」に含まれる社会的な偏見が、「学習用モデル」に学習され、不公平な出力や差別的な表現を生み出す可能性があります。
- 著作権と倫理: 生成されたコンテンツの著作権の帰属や、悪用(フェイクニュース、ディープフェイクなど)のリスクは、法整備や倫理的ガイドラインの確立を急務としています。
- 計算リソースとエネルギー消費: 大規模な「学習用モデル」の「学習」や「推論」には膨大な計算資源とエネルギーを要し、環境負荷や運用コストの増大が懸念されます。
- 透明性と説明可能性: 「学習用パラメータ」が膨大であるため、「LLM」がなぜ特定の出力をしたのか、その「仕組み」を人間が完全に理解することは困難であり、信頼性確保の課題となっています。
技術的進化の方向性
これらの課題を克服し、生成AIの可能性を最大限に引き出すために、以下のような技術的進化が期待されています。
- マルチモーダルAIの深化: テキストだけでなく、画像、音声、動画といった複数のモダリティ(形式)を統合的に理解し、生成する能力が向上します。これにより、より複雑で現実世界に近いコンテンツ生成が可能になります。
- より高度な推論と常識理解: 「LLM」が単なるパターン認識に留まらず、より深い意味理解や論理的推論、そして人間が持つような常識を学習できるようになることで、ハルシネーションの抑制や、より適切な応答が期待されます。
- パーソナライズと個別最適化: ユーザー一人ひとりの好みやニーズ、過去の行動履歴に基づき、最適なコンテンツを生成する能力が向上します。これは「追加学習」や、より洗練された「プロンプトエンジニアリング」によって実現されるでしょう。
- 効率化と持続可能性: 「学習用モデル」のアーキテクチャや「学習用パラメータ」の最適化により、より少ないデータと計算資源で高い性能を発揮するAIが開発され、エネルギー効率の向上が図られます。
- 説明可能性と信頼性(XAI): AIの意思決定プロセスを人間が理解しやすい形で提示する技術(Explainable AI: XAI)の研究が進み、生成AIの信頼性と社会受容性が高まります。
生成AIの未来は、単なる技術的な進歩だけでなく、倫理、社会、そして法制度との調和の中で形作られていきます。 「学習用データ」の公平性確保から、「プロンプト」の適切な利用ガイドライン策定まで、多角的な視点での取り組みが不可欠です。
まとめ

本記事では、生成AIの複雑な「仕組み」を、開発・学習段階から生成・利用段階まで詳細に解説しました。高品質な「学習用データセット」と適切な「「学習用パラメータ」による「学習用モデル」の構築、そして「追加学習」が、生成AIの基盤を形成します。特に、「プロンプト」による的確な「入力・指示」が、「LLM」(大規模言語モデル)の能力を最大限に引き出し、意図通りのコンテンツを「生成」する鍵であることがご理解いただけたでしょう。生成AIは、これらの要素が密接に連携することで、私たちの創造性や生産性を飛躍的に高める可能性を秘めており、今後のさらなる進化が期待されます。

プロスパイア法律事務所
代表弁護士 光股知裕
損保系法律事務所、企業法務系法律事務所での経験を経てプロスパイア法律事務所を設立。IT・インフルエンサー関連事業を主な分野とするネクタル株式会社の代表取締役も務める。企業法務全般、ベンチャー企業法務、インターネット・IT関連法務などを中心に手掛ける。









