
生成AIの学習・生成の仕組みから、文化庁「AIと著作権に関する考え方」の要点、開発・学習と生成・利用それぞれの侵害リスク、AI生成物の著作物性、検索拡張生成(RAG)や追加学習、契約・利用規約の実務対応まで、法律問題の全体像を弁護士が網羅的に解説します。
学習段階は原則適法(著作権法30条の4)だが、生成・利用で複製・翻案・公衆送信等のリスクが高く、著作物性は人の創作関与が鍵となるでしょう。
生成AIによる学習と生成の仕組みについて
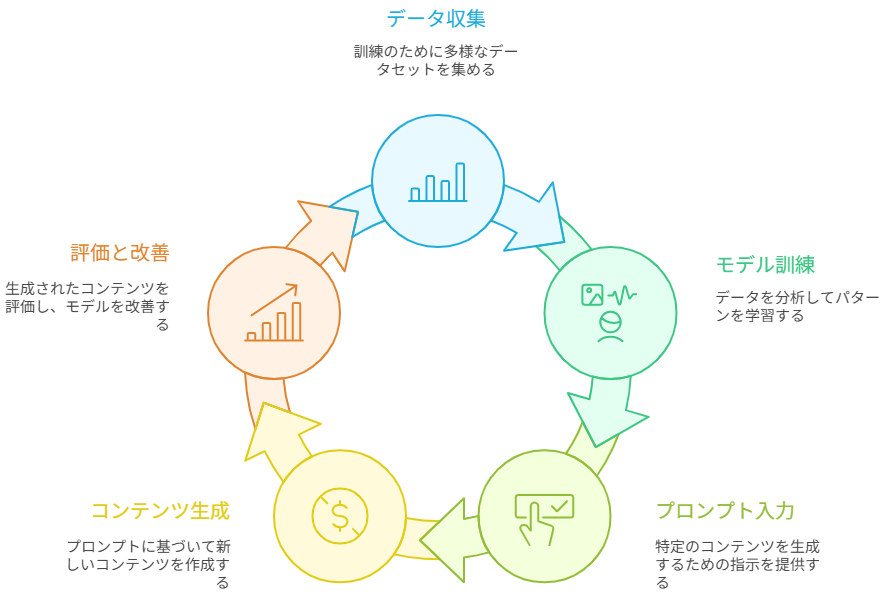
生成AI(Generative AI)は、テキスト・画像・音声といったデータから一般的なパターンを学習し、その後に与えられた指示(プロンプト)に応じて新しいコンテンツを生成する人工知能の総称です。
特に大規模言語モデル(LLM: Large Language Models)は、Transformerと呼ばれるニューラルネットワークを用い、次に現れる語(トークン)を確率的に予測する仕組みで文章を生成します。
画像分野では拡散モデルが主流で、ノイズから徐々に画像を復元する逆拡散過程で生成が行われます。
生成AIの処理は、大きく「開発・学習(訓練)」段階と「生成・利用(推論)」段階に分かれ、前者で知識と表現を獲得し、後者で個別の要求に応答します。
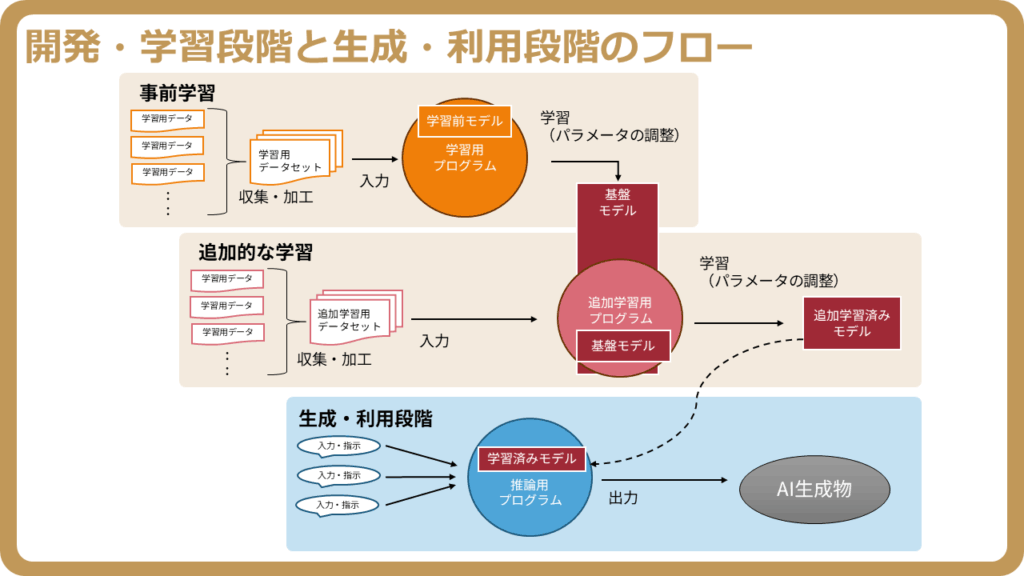
「開発・学習(訓練)」段階と「生成・利用(推論)」段階の違いや、生成AIの仕組みについては、以下の記事でも詳しく解説していますので、参考までにご参照ください。

生成AIと著作権の関係について
日本の著作権法は米国のフェアユースのような包括的条項ではなく、個別の「権利制限規定」に基づいて判断が行われます。 生成AIの法的評価も「開発・学習」と「生成・利用」の各段階で適用される権利・例外が異なるため、行為ごとに整理して検討することが重要です。
とくに、学習(テキスト・データマイニング)に関しては、著作権法の情報解析に関する規定が適用され得る一方、生成・公開のフェーズでは複製権・翻案権・公衆送信権や引用の要件が問題となります。文化庁は、AIと著作権の整理を公表し、最新の議論や方向性を示しています。
文化庁の見解「AIと著作権に関する考え方」
文化庁は、生成AIを巡る主要論点(学習段階の適法性、出力物の取り扱い、引用・出典の明示、権利制限の適用範囲など)について、「AIと著作権に関する考え方について」(令和6年3月15日)という資料を公開し、整理を示しています。
本記事の公開時点においては、この「AIと著作権に関する考え方について」という資料が、生成AIと著作権との関係に関する実務家の(一応の)共通見解といえる内容です。
生成AIに関する法的論点の整理

生成AIに関する法的論点を整理すると、まず、生成AIによる生成の過程で他の著作物を参照することの問題(=他の著作物との問題)と、生成AIによる生成物が著作粒として認められるかの問題(=生成物の著作物性の問題)に分けられます。
そして、他の著作物との問題は、生成AIによる生成の過程のうち、「開発・学習」段階と「生成・利用」段階のどこの過程の問題かにより、分けて考えられます。

生成AIによる他の著作物の著作権侵害
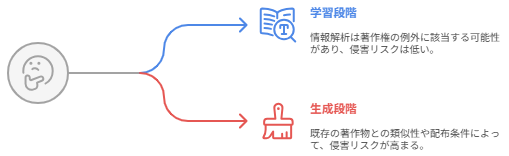
侵害の成否は、どの段階で、どのような行為が行われたかで判断されます。
大枠として、機械学習等の情報解析のために行う複製・翻案は、著作物の「表現の享受」を目的としない限り、著作権法上の権利制限(一般に「第30条の4(情報解析)」として言及)に該当し得るとされます。
もっとも、この規定が適用されるのは「情報解析のために必要と認められる範囲」に限られ、データセットや学習過程で得られた素材をそのまま外部に提供・公開する行為は、当該例外の射程を超え、複製権・公衆送信権等の侵害となり得ます。また、学習素材の取得方法がウェブサイトの利用規約違反である場合には、著作権問題に加えて契約法上の問題を生じることがあります。
生成AIの学習は広く許容され得る一方、生成物の公開・配布やデータセットの取り扱いは個別事情で結論が分かれるため、用途・態様ごとに丁寧な評価が不可欠です。
第三十条の四(著作物に表現された思想又は感情の享受を目的としない利用)
著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
著作権法(昭和四十五年法律第四十八号)
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
「開発・学習」段階
学習のための収集・複製・解析は、原則として情報解析(テキスト・データマイニング)に該当し得ます。ただし、例外の趣旨を逸脱する行為は侵害リスクが高まります。具体的には次の点に注意が必要です。
| 典型行為 | 関係する権利・規定 | 評価のポイント |
|---|---|---|
| ウェブ上の画像・文章を収集して学習に用いる | 複製権/情報解析の権利制限 | 学習目的かつ必要な範囲であれば例外適用の余地。規約違反の取得は別途リスク |
| 学習過程で作成したサムネイル・キャッシュを外部共有 | 複製権・公衆送信権 | 情報解析の範囲外となりやすく、権利者許諾が原則必要 |
| 商用モデルの再学習に著作物を利用 | 複製権/情報解析の権利制限 | 営利・非営利を問わず適用され得るが、利用は「表現の享受」目的でないことが前提 |
| 技術的保護の回避やアクセス制限の無断突破 | 著作権法上の保護手段に関する規律ほか | 学習適法性とは別に違法・不正アクセス等の問題を生じ得る |
加えて、学習データにライセンス条件(例:商用不可、要クレジットなど)が付されている場合、著作権の例外で許容される学習と、契約で制限される利用は別次元の問題であり、条件に従う必要があります。
「生成・利用」段階
出力結果の取り扱いでは、既存著作物への依拠・類似の有無、公開方法、引用の適法性などが中心論点です。次の整理が実務上有用です。
| ユーザーの行為 | 関係する権利 | 適法性判断の要点 |
|---|---|---|
| 生成画像・文章をSNSやウェブに掲載 | 公衆送信権 | 自身の創作物であれば問題なし。既存作品に依拠・類似する場合は権利者の許諾が必要になり得る |
| 特定の既存作品を入力し、スタイル変換・トレースして公開 | 複製権・翻案権(場合によっては著作者人格権) | 元作品に実質的に依拠・類似すれば侵害の可能性が高い。同一性保持権の問題を生じ得る |
| 既存作品の一部を「引用」として生成物に差し込む | 引用(著作権法32条) | 主従関係、引用の必然性、明瞭区別、出所の明示が必要。宣伝・装飾目的の寄せ集めは要件を満たしにくい |
| 他者が作成したプロンプトやLoRA等を利用して生成 | 著作権(プロンプトの表現保護の有無は個別判断)・契約 | 配布条件(ライセンス・利用規約)に従う。生成結果の権利処理とは別に契約遵守が必要 |
生成物が特定の既存著作物と実質的に同一または高度に類似し、依拠(当該作品を参考にした事実)が推認できる場合は、複製・翻案に当たる可能性が高く、公開や頒布は侵害リスクが顕在化します。 一方、単なる作風(スタイル)の模倣は、具体的表現の複製がない限り、直ちに侵害とは評価されにくいのが一般的です。
生成AIによって生成された情報の著作物性
著作権法上の著作物は、人の「思想又は感情を創作的に表現したもの」と定義されています。
第二条(定義) この法律において、次の各号に掲げる用語の意義は、当該各号に定めるところによる。
一 著作物 思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するものをいう。
著作権法(昭和四十五年法律第四十八号)
(略)
したがって、AIが自律的に出力しただけの結果は、通常は著作物性が認められにくく、人の創作的関与(選択・構成・編集・具体的指示など)が認められる場合に著作物と評価され得ます。
プロンプトの工夫や複数出力からの選択、リライト・レタッチ、画像群の選択と配列など、人の創作的寄与が認められる態様では、文章・画像・動画・音楽いずれも著作物となり得ます。逆に、機械的生成のみで人の創作性が見いだせない場合は、著作権は発生しません。
| 生成過程における人の関与 | 著作物性の見込み | 補足 |
|---|---|---|
| 単一プロンプトで自動生成し、そのまま無編集で使用 | 低い | 人の創作的表現が認めにくい |
| 多数の出力から独自の審美的判断で選択・組版・編集 | 高い | 選択・配列・編集に創作性があれば保護対象(編集著作物の可能性も) |
| 細かな指示で段階的に改稿し、具体的表現へ到達 | 高い | プロンプト設計や改稿行為に創作性が認められる |
なお、AI生成物に著作権が生じない場合でも、素材・モデル・ツールのライセンスやプラットフォームの利用規約が商用利用やクレジット表示を定めていることがあります。
現時点で生成AIと著作権に関する日本の確定判例は多くありません。実務では、権利制限規定の趣旨・要件、依拠・類似性の有無、引用の適法性、公開態様、契約条件の順に検討し、ケースごとに適切なリスクコントロールを図ることが望まれます。
AIサービスの発展とともに出てくる新しい論点
生成AIの商用実装は、基盤モデルの「学習」と「生成」を超え、検索拡張生成(RAG)や小規模データによる追加学習(ファインチューニング、LoRA、蒸留等)などサービス形態の多様化が進んでいます。これに伴い、日本の著作権法における複製権、公衆送信権、翻案権、引用(著作権法第32条)や情報解析(いわゆるテキスト・データマイニング)に関する権利制限の解釈・運用が具体的な設計論として問われます。
検索拡張生成(RAG)と著作権
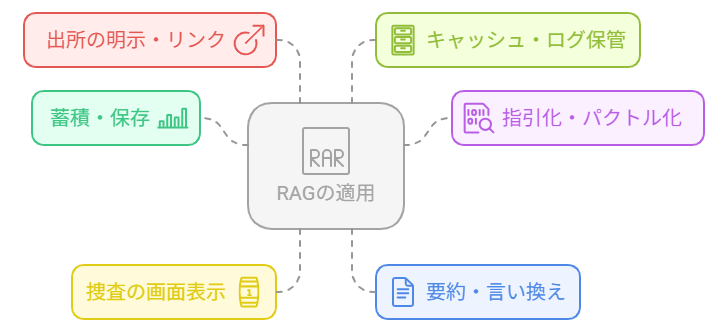
RAGは、外部コーパス(ウェブサイト、ニュース、論文、社内文書等)を検索・取得し、モデルに与えて回答を生成する手法です。インデックス作成、スニペットの抽出・表示、要約・言い換え、出所表示といった各工程で、複製権(著作権法第21条)、公衆送信権(第23条)、翻案権(第27条)、引用(第32条)や出所の明示(第48条)などが問題となり得ます。
RAGの基本構成と権利が問題となる場面
以下は、RAGの代表的な工程ごとに、該当しうる権利と適法化の方向性を要約したものです。
| 局面/行為 | 想定される権利 | 適法化の主な根拠 | 実務のポイント |
|---|---|---|---|
| 収集・保存(クロール、コーパス構築) | 複製権 | 情報解析(テキスト・データマイニング)に関する権利制限の適用可否、または明示ライセンス | 学習・索引目的の複製にとどめることの明確化、利用規約や契約の遵守、必要最小化 |
| 索引化・ベクトル化 | 複製権 | 技術的処理のための複製・情報解析の範囲 | 原文を長期保存せず、メタデータ中心の設計(必要に応じ削除手続の整備) |
| 抜粋の画面表示(スニペット提示) | 複製権・公衆送信権 | 引用(著作権法第32条)に該当させる、または表示許諾 | 主従関係・明瞭区別・必要性・出所明示(第48条)を満たすUI/UX |
| 要約・言い換え | 翻案権 | 原表現を再現しない抽象化、または要約・翻案の許諾 | 原文依存の度合いを抑制し、引用と混同しない導線 |
| 出所の明示・リンク | 出所の明示義務(引用の前提) | 著作権法第48条、引用の公正な慣行 | タイトル・著作者・URL・日時の自動付与、リンク切れ監視 |
| キャッシュ・ログ保管 | 複製権 | 処理上必要な一時的複製に関する権利制限の射程 | 保持期間の最小化、目的外利用の禁止、アクセス制御 |
RAGの「表示」部分は、引用(第32条)の要件を満たすか、明示の許諾を得るかという設計判断が中心となります。
「引用」に関しては、以下の法律記事でも詳しく解説していますので、参考までにご参照ください。

第三十二条(引用) 公表された著作物は、引用して利用することができる。この場合において、その引用は、公正な慣行に合致するものであり、かつ、報道、批評、研究その他の引用の目的上正当な範囲内で行なわれるものでなければならない。
著作権法(昭和四十五年法律第四十八号)
2 国等の周知目的資料は、説明の材料として新聞紙、雑誌その他の刊行物に転載することができる。ただし、これを禁止する旨の表示がある場合は、この限りでない。
引用と要約・要旨化の境界
引用は、出所の明示(著作権法第48条)や、主従関係・明瞭区別・必要性といった「公正な慣行」による枠組みが要請されます(著作権法第32条)。これに対し、要約や言い換えは内容の抽象化・再構成を伴い、個別事案では翻案権の問題が生じ得ます。RAGでは、原文の大部引用を避け、引用部分を明確に区切り、モデル生成部分と視覚的に分離し、要約は原表現の再現度を抑える設計が望まれます。
第四十八条(出所の明示)
1 次の各号に掲げる場合には、当該各号に規定する著作物の出所を、その複製又は利用の態様に応じ合理的と認められる方法及び程度により、明示しなければならない。
一 第三十二条、第三十三条第一項(同条第四項において準用する場合を含む。)、第三十三条の二第一項、第三十三条の三第一項、第三十七条第一項、第四十一条の二第一項、第四十二条、第四十二条の二第一項又は第四十七条第一項の規定により著作物を複製する場合
二 第三十四条第一項、第三十七条第三項、第三十七条の二、第三十九条第一項、第四十条第一項若しくは第二項、第四十七条第二項若しくは第三項又は第四十七条の二の規定により著作物を利用する場合三 第三十二条若しくは第四十二条の規定により著作物を複製以外の方法により利用する場合又は第三十五条第一項、第三十六条第一項、第三十八条第一項、第四十一条、第四十一条の二第二項、第四十二条の二第二項、第四十六条若しくは第四十七条の五第一項の規定により著作物を利用する場合において、その出所を明示する慣行があるとき。2 前項の出所の明示に当たつては、これに伴い著作者名が明らかになる場合及び当該著作物が無名のものである場合を除き、当該著作物につき表示されている著作者名を示さなければならない。
3 次の各号に掲げる場合には、前二項の規定の例により、当該各号に規定する二次的著作物の原著作物の出所を明示しなければならない。一 第四十条第一項、第四十六条又は第四十七条の五第一項の規定により創作された二次的著作物をこれらの規定により利用する場合
著作権法(昭和四十五年法律第四十八号)
二 第四十七条の六第一項の規定により創作された二次的著作物を同条第二項の規定の適用を受けて同条第一項各号に掲げる規定により利用する場合
オンライン表示時の公衆送信と一時的複製
RAGの結果をウェブやアプリで不特定又は多数の者に提示する場合、公衆送信権(著作権法第23条)が問題となり得ます。加えて、検索・生成処理に伴うキャッシュや一時的な複製は、技術的過程で不可避な範囲に限られるべきで、保持期間やアクセス権限の管理が重要です。
RAG適法化の設計指針(チェックリスト)
以下は、RAGを適法に運用するための実装上の指針をまとめたものです。
| 設計項目 | 推奨アプローチ |
|---|---|
| 引用表示 | 引用符・枠などで明確に区別、主従関係をUIで担保、出所(タイトル・著作者・URL・日時)の自動明示 |
| 要約生成 | 原表現の再現を抑制、必要最小限の引用と組合せ、原文の大部再現を回避 |
| データ収集 | 目的限定・保持最小化、契約・利用規約の遵守、削除請求への対応フロー |
| ログ・キャッシュ | 保持期間とアクセス権限を最小化、目的外利用を禁止 |
| ライセンス素材 | CC等の条件検証を自動化、混在データのコンプライアンス監査 |
検索体験の利便性を高めつつ、表示は「引用」、要約は「翻案」に触れない抽象化という住み分けをUIと技術で徹底することが、RAGの適法運用の核心です。
小規模なデータセットによる追加学習で偏った生成をする方法と著作権
追加学習(ファインチューニング、LoRA、パラメータ効率化学習、指示チューニング等)は、比較的少量のデータで特定の作風・語り口・ドメイン知識へモデル出力を「偏らせる」手法です。データ収集・学習・配布・出力管理の各段階で、著作権法の権利制限(情報解析)、複製権・翻案権、引用、さらに契約(利用規約・ライセンス)遵守が論点となります。
追加学習データの収集・利用(情報解析と契約の関係)
学習のための複製・解析については、著作権法上の権利制限(情報解析)に該当し得る一方、データの取得源が有償データベースやAPI、サブスクリプション等である場合は、契約・利用規約で機械学習利用が制限されていることがあります。この場合、著作権侵害の成否とは別に、契約違反の問題が独立に発生し得るため、ライセンスの範囲確認が必須です。
| データ出所 | 主な法的根拠 | 主なリスク | 推奨対策 |
|---|---|---|---|
| 公開ウェブ | 情報解析の権利制限、またはサイト許諾 | 利用規約違反、権利者の意図しない再利用 | 収集ポリシーの明確化、除外・削除要請に対応、必要最小限の保持 |
| 有償DB・API | 契約・利用許諾 | 学習利用の非許諾、再配布制限 | 契約条項のレビュー、用途限定、監査ログの整備 |
| オープンライセンス(CC等) | ライセンス条件 | 表示義務、非営利・継承条件の不履行 | メタデータ管理、出所表示自動化、条件ごとの分離学習 |
| 自社保有資料 | 自社の権利・契約 | 第三者権利の混入 | 権利クリアランス、アクセス制御、漏えい防止 |
特定作家の「作風」模倣と著作権侵害の判断枠組み
日本の著作権法は「アイデア」や「作風」それ自体を直接保護しませんが、特定の既存作品の創作的表現上の本質的特徴が直接感得できる程度に出力が似ている場合には、既存作品の複製・翻案が問題となる余地があります。追加学習で特定作家の作品を多数含めた場合、構図・配色・モチーフの具体的表現が反復再現されるリスクが高まるため、データの選別、重複除去、近接出力の類似度検知、人手レビュー等のガードレールを備えることが重要です。
追加学習モデルの配布・API提供と「記憶(過学習)」のリスク
追加学習後のモデルを配布・提供する場合、モデルが学習データの断片を再現しやすくなる「記憶(過学習)」が問題となり得ます。第三者が通常のプロンプトで再現性高く著作物の表現を復元できる場合には、複製権侵害のリスクが顕在化します。モデル監査(トリガープロンプト探索、出力フィルタリング、データ削除に応じた再学習・重み更新)、配布前のガバナンス体制(責任者・手続の明確化)が必要です。
実装ガイドライン(プロダクト設計)
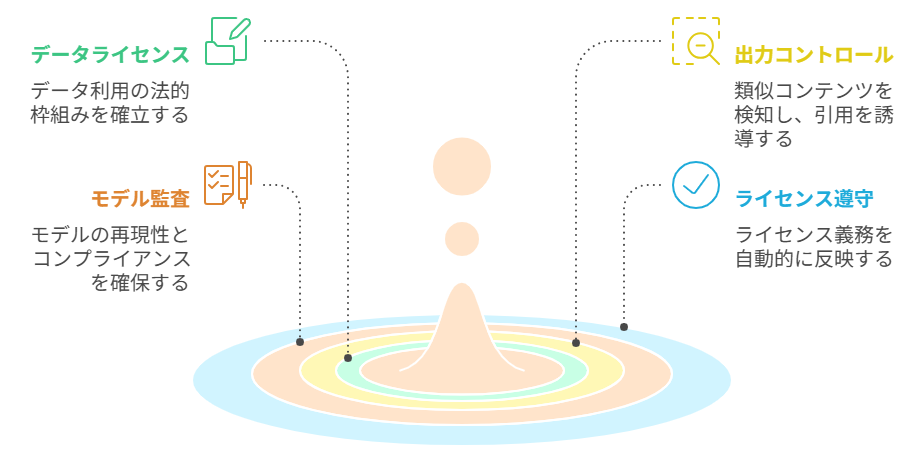
小規模追加学習を前提としたサービス設計における、著作権対応の勘所は次のとおりです。
| 領域 | 推奨実装 |
|---|---|
| データライセンス | 取得源・条件の台帳化、利用目的の限定、条件不明データの除外 |
| 出力コントロール | 高類似出力の検知・ブロック、引用誘導(出所明示)UI、プロンプト制約 |
| モデル監査 | 再現性テスト、ログ保存期間の最小化、削除請求対応のプロセス |
| ライセンス遵守 | CC等の表示義務を自動反映、条件違反時の停止フロー |
「作風」レベルの誘導に留め、特定作品の表現を再現させない技術・運用(データ管理、出力監視、引用誘導)の三点セットが、追加学習サービスの実務的な著作権対策の中核です。
まとめ
生成AIの法的論点は、大きく分けてAIによる生成が他の著作物の著作権侵害とならないかという問題と、AIによる生成物が著作物といえるかの問題に分けられます。
前者は、「開発・学習」と「生成・利用」で異なるものと整理されており、文化庁の見解では、学習利用は著作権法第30条の4で一定範囲許容。一方、生成物が既存の作品に依拠し実質的に類似すれば侵害の余地があるものと考えられています。
後者については、創作性の乏しい出力は著作物でなく、人の創作的関与があれば保護対象となるという整理です。
また、AIを使った新しいサービスとの関係では、検索拡張生成(RAG)は引用要件やライセンス、追加学習は依拠性に留意する必要があります。
以上のように、生成AIと著作権の問題を正しく理解するためには、著作権の理解はもとより、生成AI自体の理解も必要になります。また、新しいサービスの発展とともに、随時新しい論点も生まれるため、詳細は専門家に相談をしましょう。

プロスパイア法律事務所
代表弁護士 光股知裕
損保系法律事務所、企業法務系法律事務所での経験を経てプロスパイア法律事務所を設立。IT・インフルエンサー関連事業を主な分野とするネクタル株式会社の代表取締役も務める。企業法務全般、ベンチャー企業法務、インターネット・IT関連法務などを中心に手掛ける。









